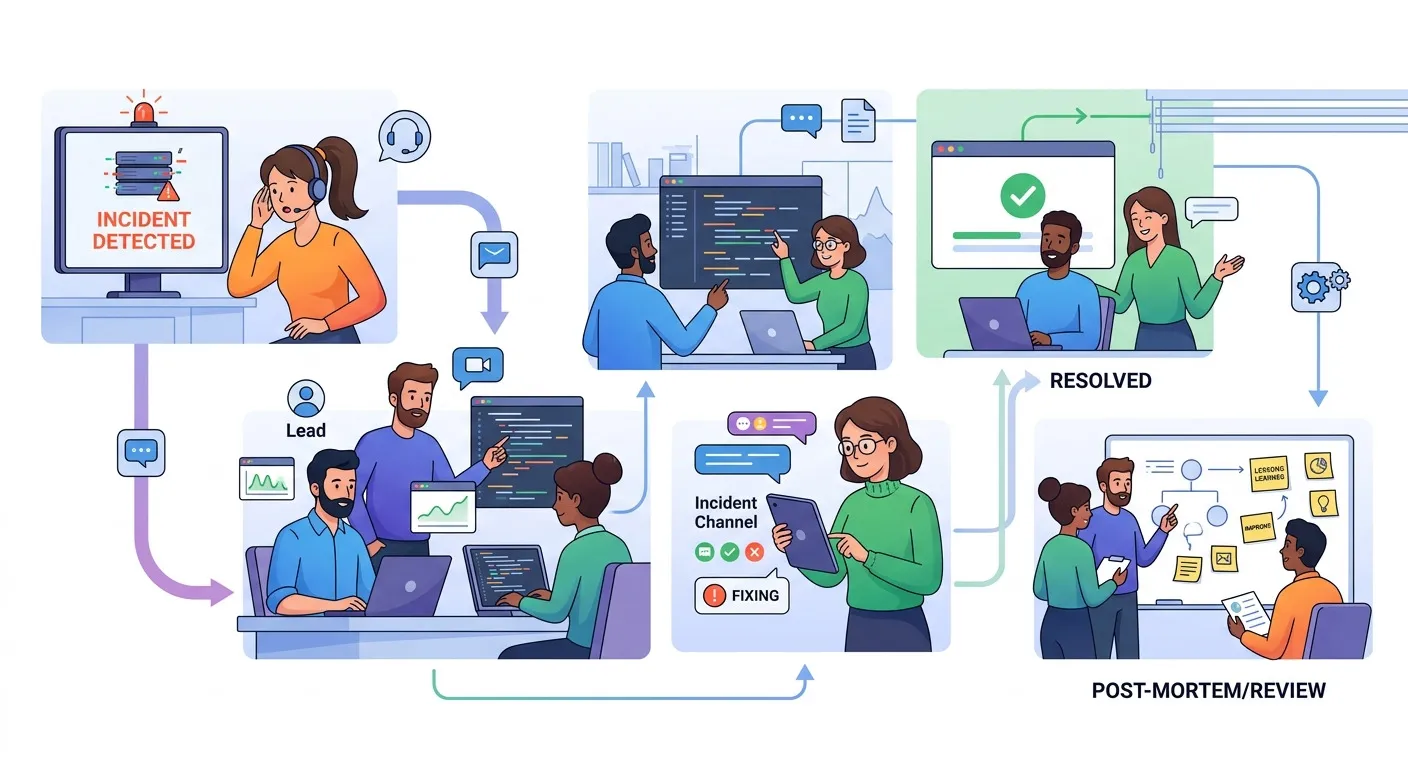
Incident Response for Small Teams: Staying Calm During Production Errors
Table of Contents
- Why Incident Response Matters for Small Teams?
- Incident Response Framework for Small Teams
- Phase 1: Detection & Acknowledgment (0-5 minutes)
- Phase 2: Investigation & Triage (5-30 minutes)
- Phase 3: Resolution & Recovery (30+ minutes)
- Phase 4: Post-Mortem & Learning
- Communication Templates
- Tooling for Small Teams
- Common Pitfalls & Solutions
- Incident Response Checklist
Why Incident Response Matters for Small Teams?
Small teams often face unique challenges when production errors occur:
- Limited resources - only a few people are available
- High pressure - everyone wears multiple hats
- Customer impact - errors are directly felt by users
- Learning opportunity - every incident is a chance for improvement
Good incident response isn’t about preventing errors—it’s about minimizing damage and learning from experience.
Incident Response Framework for Small Teams
This framework is adapted for teams of 2-5 people with focus on speed and clarity:
Incident Response Timeline:
├── 0-5 minutes: Detection & Acknowledgment
│ ├── Monitor alerts trigger
│ ├── Initial impact assessment
│ ├── Declare incident & form channel
│ └── Communicate status
├── 5-30 minutes: Investigation & Triage
│ ├── Gather context & logs
│ ├── Identify root cause area
│ ├── Determine severity level
│ └── Assign incident commander
├── 30+ minutes: Resolution & Recovery
│ ├── Implement fix (temporary/permanent)
│ ├── Monitor recovery
│ ├── Verify service restoration
│ └── Update stakeholders
└── Post-Incident: Learning
├── Write post-mortem
├── Identify action items
├── Update processes
└── Share learningsPhase 1: Detection & Acknowledgment (0-5 minutes)
Alert Detection
Set up comprehensive but not overwhelming monitoring:
# Example alert configuration
alerts:
critical:
- service_down_5min
- error_rate_50percent
- response_time_5x_baseline
warning:
- error_rate_increase_20percent
- memory_usage_80percent
- queue_depth_1000Initial Response Script
The first person to detect an incident should:
-
Acknowledge immediately in the monitoring system
-
Create incident channel in Slack/Teams
-
Post initial update with template:
🚨 INCIDENT DECLARED 🚨 Service: [Service Name] Time: [Timestamp] Impact: [Initial assessment] Severity: [Critical/High/Medium/Low] Next update in 15 minutes or when new info available. -
Tag relevant people based on on-call rotation
Severity Assessment
Use this framework to determine severity:
| Severity | Impact | Response Time | Example |
|---|---|---|---|
| Critical | Complete service outage | < 5 minutes | Login doesn’t work |
| High | Major feature broken | < 15 minutes | Payment processing fails |
| Medium | Partial degradation | < 1 hour | Reports slow |
| Low | Minor issue | < 4 hours | UI glitch |
Phase 2: Investigation & Triage (5-30 minutes)
Role Assignment
For small teams, assign flexible roles:
incident_roles:
incident_commander:
responsibilities:
- Coordinate response
- Manage communications
- Make final decisions
backup: "Senior engineer on-call"
technical_lead:
responsibilities:
- Lead investigation
- Coordinate technical fixes
- Verify resolution
backup: "Any available engineer"
communications_lead:
responsibilities:
- Update stakeholders
- Manage customer comms
- Document timeline
backup: "Product manager or support lead"Investigation Process
Step 1: Gather Context (5-10 minutes)
- Check recent deployments
- Review error logs and metrics
- Identify affected components
- Check external dependencies
Step 2: Isolate Problem (10-20 minutes)
- Reproduce issue in staging
- Test hypotheses
- Narrow down root cause area
- Document findings in incident channel
Step 3: Determine Fix Strategy (20-30 minutes)
fix_strategy:
immediate_actions:
- Rollback deployment?
- Restart services?
- Scale resources?
- Fallback to cached data?
permanent_solution:
- Code fix needed?
- Configuration change?
- Infrastructure update?
- Process improvement?Phase 3: Resolution & Recovery (30+ minutes)
Implementation Guidelines
For temporary fixes:
- Prioritize speed over perfection
- Document what was changed
- Set reminder for permanent fix
- Monitor for side effects
For permanent fixes:
- Test in staging first
- Plan rollback strategy
- Communicate maintenance window
- Monitor post-deployment
Recovery Verification
Checklist for verification:
- Service health checks passing
- Key user journeys working
- Metrics returned to baseline
- No new errors in logs
- Customer reports resolved
Communication Updates
Update every 15-30 minutes or when there are significant changes:
📊 INCIDENT UPDATE 📊
Status: [Investigating/Mitigated/Resolved]
Time: [Timestamp]
Impact: [Current state]
Actions: [What we've done]
ETA: [If available]
Next update: [Time or "when new info"]Phase 4: Post-Mortem & Learning
Blameless Post-Mortem Template
# Incident Post-Mortem: [Incident Title]
## Summary
[Brief description of what happened and impact]
## Timeline
- **HH:MM**: Alert triggered
- **HH:MM**: Incident declared
- **HH:MM**: Root cause identified
- **HH:MM**: Fix implemented
- **HH:MM**: Service restored
## Root Cause
[What actually caused the incident]
## Impact
- Users affected: [Number/Percentage]
- Duration: [Time]
- Business impact: [Description]
## What Went Well
- [Positive aspects of response]
## What Could Be Improved
- [Areas for improvement]
## Action Items
- [ ] [Specific action] - [Owner] - [Due date]
- [ ] [Specific action] - [Owner] - [Due date]Learning Loop
- Review action items within 1 week
- Update monitoring based on learnings
- Improve processes and documentation
- Share learnings with entire team
- Update on-call training if needed
Communication Templates
Customer Communication
Initial Notification:
Subject: Service Issue - [Service Name]
Hi [Customer Name],
We're currently experiencing issues with [service description].
Our team is actively investigating and working to resolve this.
We'll provide updates every [X] minutes until this is resolved.
Thank you for your patience.
Team [Company Name]Resolution Notification:
Subject: Resolved - Service Issue - [Service Name]
Hi [Customer Name],
The issue with [service description] has been resolved.
Service is now operating normally.
We're conducting a full review to prevent this from happening again.
If you continue to experience issues, please contact support.
Thank you for your patience.
Team [Company Name]Internal Stakeholder Updates
Executive Summary:
🚨 PRODUCTION INCIDENT 🚨
Service: [Service]
Severity: [Level]
Impact: [Business impact]
Timeline: [Start - Resolution]
Root Cause: [Brief description]
Customer Impact: [Number/Type]
Next Steps: [Post-mortem scheduled]Tooling for Small Teams
Essential Tools
monitoring:
- Application performance monitoring (APM)
- Infrastructure monitoring
- Log aggregation
- Alert management
communication:
- Incident response platform (Slack/Teams)
- Status page
- Email notification system
- Video conferencing
documentation:
- Runbook repository
- Post-mortem template
- Contact information
- Service topologyRecommended Stack for Small Teams
Monitoring:
- Uptime monitoring: UptimeRobot, Pingdom
- APM: Sentry, New Relic (free tier)
- Logs: Papertrail, Logtail
- Metrics: Prometheus + Grafana (self-hosted)
Communication:
- Incident channel: Slack #incidents
- Status page: Statuspage.io, Cachet
- Documentation: Notion, Confluence
Automation:
- Alert routing: PagerDuty (free tier)
- Runbook execution: GitHub Actions
- Post-mortem: Template + automation
Common Pitfalls & Solutions
Pitfall 1: No Clear Incident Commander
Problem: Everyone tries to lead, nobody takes charge.
Solution:
- Pre-define on-call rotation
- Use escalation matrix
- Practice incident simulations
Pitfall 2: Poor Communication
Problem: Stakeholders left in the dark, rumors spread.
Solution:
- Use communication templates
- Set regular update intervals
- Over-communicate rather than under-communicate
Pitfall 3: Rushing to Fix Without Understanding
Problem: Making things worse while trying to help.
Solution:
- Take 5 minutes to assess before acting
- Document changes before implementing
- Have rollback plan ready
Pitfall 4: No Post-Mortem Process
Problem: Same incidents happen repeatedly.
Solution:
- Schedule post-mortem within 48 hours
- Make action items specific and assignable
- Track completion of action items
Pitfall 5: Alert Fatigue
Problem: Too many alerts, ignored warnings.
Solution:
- Regularly review alert thresholds
- Implement alert grouping
- Use severity levels appropriately
Incident Response Checklist
Pre-Incident Preparation
- On-call schedule defined and communicated
- Contact information up to date
- Monitoring alerts configured and tested
- Runbooks created for common scenarios
- Communication templates prepared
- Status page setup and configured
- Incident response training completed
During Incident (0-5 minutes)
- Acknowledge alert in monitoring system
- Create incident channel
- Post initial status update
- Tag relevant team members
- Assess initial impact
- Determine severity level
During Incident (5-30 minutes)
- Assign incident commander role
- Gather logs and metrics
- Identify affected components
- Form hypothesis about root cause
- Document investigation findings
- Plan fix strategy
During Incident (30+ minutes)
- Implement fix (temporary or permanent)
- Monitor service recovery
- Verify key functionality
- Update stakeholders on resolution
- Close incident in monitoring system
Post-Incident (Within 48 hours)
- Schedule post-mortem meeting
- Complete incident timeline
- Identify root cause
- Create action items with owners
- Share learnings with team
- Update documentation and runbooks
Continuous Improvement
- Review action items weekly
- Update monitoring based on incidents
- Conduct quarterly incident drills
- Measure MTTR (Mean Time to Resolution)
- Celebrate improvements and learning
Conclusion
Effective incident response for small teams isn’t about having perfect processes—it’s about having consistent, practiced responses that scale with team size and resources.
Key principles for small teams:
- Simplicity over complexity - processes that are easy to follow
- Communication is critical - over-communicate during incidents
- Learning over blaming - focus on improvement not punishment
- Practice makes perfect - regular drills and simulations
- Tools enable, people solve - technology supports, not replaces
This framework provides enough structure for consistency but is flexible enough for small team realities. Adapt to your specific team needs, but maintain core principles: clear communication, defined roles, and commitment to learning.
Remember: Good incident response is a skill that improves with practice. Start small, be consistent, and continuously improve based on real incidents.
Related Articles
What’s the most memorable incident experience for your team? Share your stories and lessons learned in the comments—we can all learn together!