SQL Query Tuning Praktis: Performa Naik Tanpa Ganti Arsitektur
Daftar Isi
- Mulai dari Gejala: Kapan Kamu Harus Tuning Query?
- Langkah 1: Temukan Query Paling Mahal dengan Slow Log
- Langkah 2: Baca Execution Plan Tanpa Panik
- Langkah 3: Pilih dan Desain Indeks yang Tepat
- Anti-Pattern Query yang Paling Sering Ditemui
- Studi Kasus: Sebelum dan Sesudah Tuning
- Kapan Tuning Tidak Cukup dan Perlu Solusi Lain?
Mulai dari Gejala: Kapan Kamu Harus Tuning Query?
Sebelum buru-buru menambah indeks atau mengganti ORM, penting untuk memastikan masalahnya memang di query, bukan di tempat lain (aplikasi lambat start, network bermasalah, service lain overload).
Beberapa gejala khas masalah query:
- Endpoint tertentu tiba-tiba melambat saat traffic naik, padahal logic aplikasinya sederhana.
- Database CPU usage melonjak tinggi walaupun jumlah request tidak terlalu besar.
- Ada laporan “page X sering timeout” dan saat dicek, selalu berhenti di operasi baca/tulis database.
Tanda lain yang lebih halus:
- Query yang dulunya cepat mulai melambat setelah data tumbuh beberapa kali lipat.
- Report atau batch job yang tadinya selesai dalam hitungan menit, sekarang butuh setengah jam lebih.
Daripada menebak-nebak, kamu butuh:
- Data observabilitas: log, metric, trace.
- Cara sistematis untuk menemukan query mana yang paling bikin repot.
Itulah yang akan dibahas di langkah berikutnya: mulai dari slow log, lanjut ke execution plan, baru kemudian desain indeks dan perbaikan pola query.
Langkah 1: Temukan Query Paling Mahal dengan Slow Log
Alih-alih men-tuning semua query, fokus dulu ke sedikit query yang paling mahal. Biasanya Pareto berlaku: 20% query menyumbang 80% masalah performa.
Langkah praktis:
- Aktifkan slow query log (fitur tersedia di MySQL, PostgreSQL, dsb).
Atur threshold yang masuk akal, misalnya:- 500 ms untuk API sync.
- Lebih longgar untuk job batch.
- Kumpulkan dan agregasi:
- Kelompokkan query berdasar template (bukan per value literal).
- Hitung berapa kali muncul dan rata-rata durasinya.
- Urutkan berdasarkan dampak:
- Kombinasi antara frekuensi tinggi + durasi tinggi.
- Hindari terjebak hanya mengejar outlier yang jarang terjadi.
Jika kamu punya APM/observability (New Relic, Datadog, OpenTelemetry, dsb), gunakan:
- Dashboard “slow query” bawaan.
- Trace end-to-end untuk melihat proporsi waktu di DB vs di aplikasi.
Hasil akhir dari langkah ini sebaiknya berupa daftar pendek (misalnya 5–10 query) yang layak dianalisis lebih dalam, lengkap dengan:
- Contoh query,
- Tabel yang disentuh,
- Rata-rata durasi dan p95/p99,
- Endpoint atau job yang memakainya.
Langkah 2: Baca Execution Plan Tanpa Panik
Execution plan (EXPLAIN) sering terlihat menakutkan, tapi ada beberapa hal kunci yang hampir selalu penting:
- Jenis scan:
Seq Scan/ table scan: baca seluruh tabel.Index Scan/Index Seek: pakai indeks secara efektif.Index Only Scan: lebih efisien karena hanya baca indeks.
- Estimate vs actual rows (kalau pakai
EXPLAIN ANALYZE):- Kalau estimasi jauh meleset, berarti statistik tidak akurat → planner pilih rencana yang jelek.
- Node yang paling mahal:
- Lihat
costdan waktu aktual di setiap node. - Cari bagian yang memakan persentase terbesar dari total eksekusi.
- Lihat
Pola masalah yang sering muncul:
- Filter dan join dilakukan tanpa indeks di kolom yang dipakai di
WHERE/JOIN. - Penggunaan fungsi di kolom indeks (
LOWER(column),DATE(column)) sehingga indeks tidak bisa dipakai langsung. - Sort (
ORDER BY) besar tanpa indeks pendukung → butuh sort di memory/disk.
Strategi membaca execution plan:
- Jalankan query dengan
EXPLAIN ANALYZE. - Tandai node paling mahal (waktu dan rows).
- Tanyakan: “Bagaimana caranya mengurangi jumlah baris yang lewat node ini?”
Biasanya jawabannya adalah indeks yang tepat atau perbaikan kondisi filter/join.
Langkah 3: Pilih dan Desain Indeks yang Tepat
Indeks bisa jadi penyelamat, tapi juga bisa jadi beban kalau terlalu banyak atau didesain asal. Yang penting bukan “banyak indeks”, tapi indeks yang tepat untuk pola query yang nyata dipakai.
Beberapa prinsip dasar:
- Index mengikuti query, bukan sebaliknya: selalu desain indeks berdasarkan pola
WHERE,JOIN, danORDER BYyang benar-benar terjadi. - Urutan kolom di indeks komposit penting:
- Letakkan kolom dengan selektivitas tinggi lebih dulu (yang paling banyak menyaring data).
- Pertimbangkan pola filter:
WHERE status = ? AND created_at BETWEEN ? AND ?→ indeks(status, created_at)sering masuk akal.
- Gunakan indeks partial / filtered (kalau DB mendukung):
- Misalnya hanya mengindeks row dengan
status = 'ACTIVE'jika itu kasus paling sering diakses.
- Misalnya hanya mengindeks row dengan
Contoh sederhana di PostgreSQL:
CREATE INDEX idx_orders_status_created_at
ON orders (status, created_at DESC);Tips praktis:
- Jangan buru-buru bikin indeks baru untuk setiap query; cek dulu apakah indeks yang ada bisa disesuaikan.
- Waspadai overhead:
- Setiap indeks baru memperlambat operasi
INSERT/UPDATE/DELETE. - Terlalu banyak indeks bisa membuat planner makin bingung memilih rencana terbaik.
- Setiap indeks baru memperlambat operasi
Idealnya, kamu punya review berkala untuk:
- Menghapus indeks yang sudah tidak terpakai (lihat statistik
idx_scan/ penggunaan). - Menyederhanakan beberapa indeks yang redundant.
Anti-Pattern Query yang Paling Sering Ditemui
Beberapa pola query berikut hampir selalu memicu masalah performa kalau dibiarkan di sistem yang datanya terus tumbuh:
-
SELECT *di tabel besar tanpa filter yang jelas- Ambil terlalu banyak kolom dan baris.
- Sulit meng-optimize karena DB tidak tahu kolom mana yang benar-benar penting.
-
Filter di aplikasi, bukan di DB
- Query mengambil banyak data, lalu disaring di code (misalnya di loop).
- Lebih baik kirimkan kondisi langsung di
WHEREatauJOIN.
-
Wildcard di awal pattern (
LIKE '%abc')- Hampir selalu memaksa full scan, karena indeks tidak bisa digunakan dengan baik.
- Pertimbangkan solusi lain (misalnya reverse index, search engine, atau requirement yang direvisi).
-
Over-join tanpa kebutuhan jelas
- Query meng-join banyak tabel hanya demi mengambil 1–2 kolom.
- Kadang bisa dipecah menjadi dua query yang lebih sederhana dan mudah di-cache.
-
N+1 query
- Misalnya: ambil daftar order, lalu untuk setiap order ambil item-nya dengan query terpisah.
- Solusi: join yang tepat atau batching query (IN clause), atau gunakan fitur eager loading ORM dengan hati-hati.
Membuat checklist anti-pattern ini dan mengintegrasikannya ke code review akan mengurangi banyak masalah performa di masa depan.
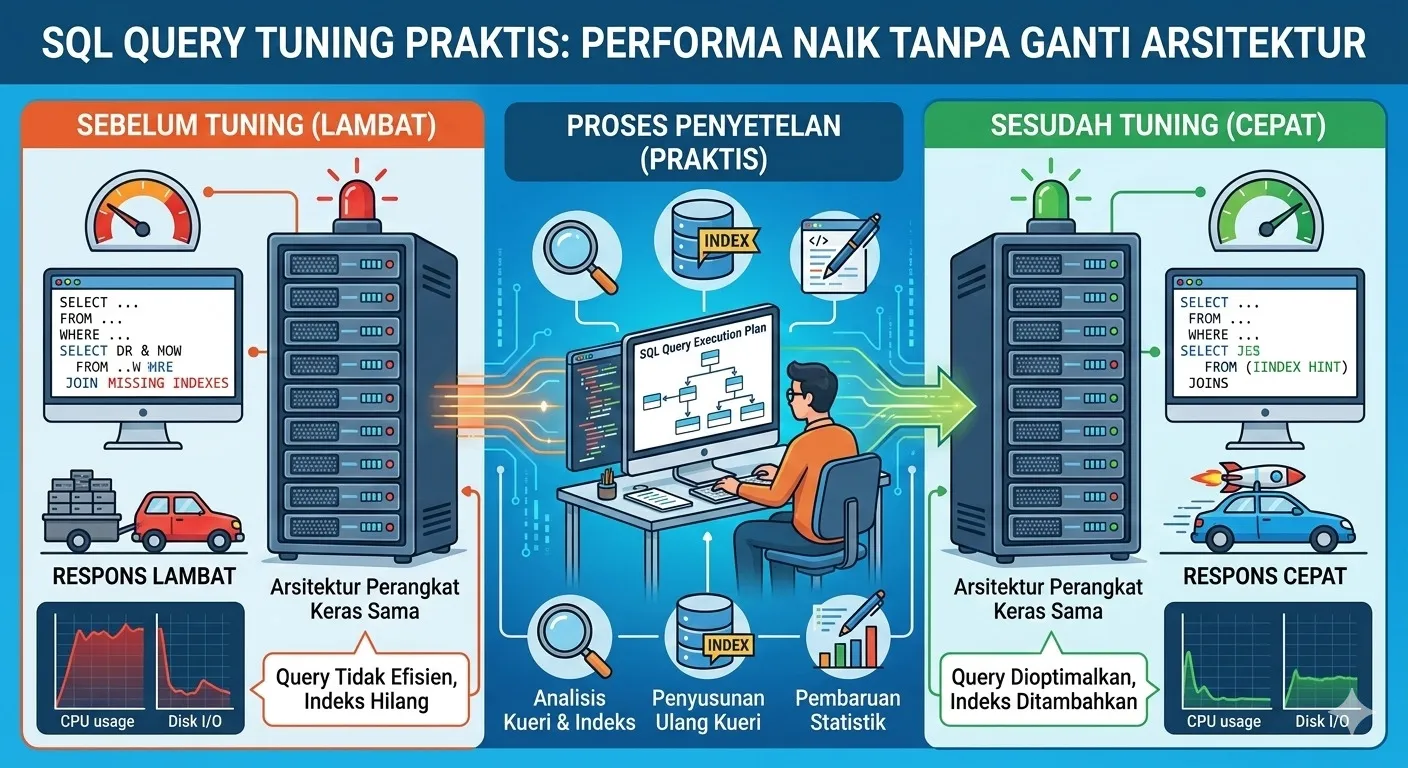
Studi Kasus: Sebelum dan Sesudah Tuning
Bayangkan sebuah endpoint: “List order terbaru customer dengan filter status” yang lambat saat data sudah ratusan ribu baris.
Query awal:
SELECT *
FROM orders
WHERE customer_id = $1
AND status IN ('PAID', 'SHIPPED')
ORDER BY created_at DESC
LIMIT 20;Gejala:
- Waktu eksekusi mendekati 1–2 detik untuk customer yang sangat aktif.
- Execution plan menunjukkan
Seq Scandi tabelorders.
Langkah tuning:
- Tambahkan indeks komposit:
CREATE INDEX idx_orders_customer_status_created_at ON orders (customer_id, status, created_at DESC); - Review kolom yang di-select:
- Jika UI hanya butuh beberapa kolom (misalnya
id, total_amount, created_at, status), ubah query untuk hanya mengambil kolom tersebut.
- Jika UI hanya butuh beberapa kolom (misalnya
- Pastikan statistik up to date:
- Jalankan
ANALYZEatau pastikan autovacuum/statistics berjalan normal.
- Jalankan
Hasil:
- Execution plan beralih ke
Index Scandengan rows yang jauh lebih sedikit. - Waktu eksekusi turun drastis (misalnya dari 1.5 detik ke < 100 ms).
Poin penting: tidak ada perubahan arsitektur besar, hanya:
- Indeks yang tepat,
- Query yang lebih hemat data,
- Statistik yang sehat.
Kapan Tuning Tidak Cukup dan Perlu Solusi Lain?
Tidak semua masalah performa bisa diselesaikan hanya dengan tuning query dan indeks. Beberapa sinyal bahwa kamu butuh solusi yang lebih besar:
- Setelah indeks dan query dioptimasi, resource DB tetap penuh dan antrian request tetap mengular.
- Pola akses data berubah: sekarang ada report kompleks yang membaca hampir seluruh tabel secara rutin.
- Beban read/write tumbuh jauh lebih cepat dari kemampuan satu instance database.
Pilihan solusi di luar tuning query:
- Sharding atau partitioning:
- Membagi data berdasarkan key tertentu (misalnya per tenant, per tanggal).
- Mengurangi jumlah data yang perlu dipindai per query.
- Read replica:
- Memindahkan beban baca yang berat ke replika.
- Cocok untuk report, dashboard, atau endpoint yang mostly-read.
- Caching di layer aplikasi:
- Meng-cache result query yang berat tapi sering diulang dengan parameter sama.
- Bisa pakai Redis, in-memory cache, atau mekanisme HTTP caching.
- Search engine / analitik terpisah:
- Untuk pencarian teks kompleks atau analitik berat, pertimbangkan Elasticsearch, OpenSearch, ClickHouse, dsb.
Yang penting: selalu mulai dari tuning yang murah (query & indeks) sebelum lompat ke solusi besar. Tapi juga jangan memaksa satu database monolith untuk menanggung semua jenis beban tanpa batas.
Referensi
- Use the Index, Luke — Markus Winand
- PostgreSQL EXPLAIN Documentation
- MySQL Performance Blog — Percona
- High Performance MySQL — Baron Schwartz et al.
Artikel Terkait
- Database Design Fundamentals
- Bangun API Type-Safe dengan TypeScript dari Awal
- Observability 101: Logs, Metrics, Traces untuk Tim Modern
Pernah nemuin query yang awalnya tampak wajar tapi ternyata bikin server keringat dingin? Atau ada trik tuning yang bikin performa naik drastis? Ceritakan di komentar — kasus nyata selalu jadi bahan belajar terbaik! 💬