RAG vs Fine-Tuning: Kapan Menggunakan Masing-Masing Pendekatan
Daftar Isi
- Pendahuluan
- Memahami RAG (Retrieval-Augmented Generation)
- Memahami Fine-Tuning
- Dimensi Perbandingan Utama
- Matriks Perbandingan
- Kerangka Keputusan: Kapan Menggunakan Apa
- Pendekatan Hybrid: RAG + Fine-Tuning
- FAQ
- Kesimpulan
Pendahuluan
Saat membangun aplikasi generative AI tingkat enterprise, developer dihadapkan pada pertanyaan arsitektur yang penting: bagaimana cara menyesuaikan Large Language Model (LLM) agar dapat bekerja dengan data internal perusahaan dan melakukan tugas-tugas spesifik?
Secara garis besar, dua metodologi utama mendominasi lanskap ini: Retrieval-Augmented Generation (RAG) dan Fine-Tuning. Meskipun sering kali dibahas sebagai opsi yang bersaing, keduanya sebenarnya menyelesaikan masalah yang mendasarinya secara berbeda. RAG berfokus pada pemberian akses model ke pengetahuan eksternal yang dinamis, sedangkan Fine-Tuning berfokus pada modifikasi perilaku, gaya, atau performa model untuk tugas tertentu.
Memilih pendekatan yang salah dapat menyebabkan biaya komputasi yang tinggi, data yang basi, dan pengalaman pengguna yang buruk. Artikel ini membandingkan RAG dan Fine-Tuning di berbagai dimensi utama untuk membantu Kamu memilih pola arsitektur terbaik untuk aplikasi Kamu.
Memahami RAG (Retrieval-Augmented Generation)
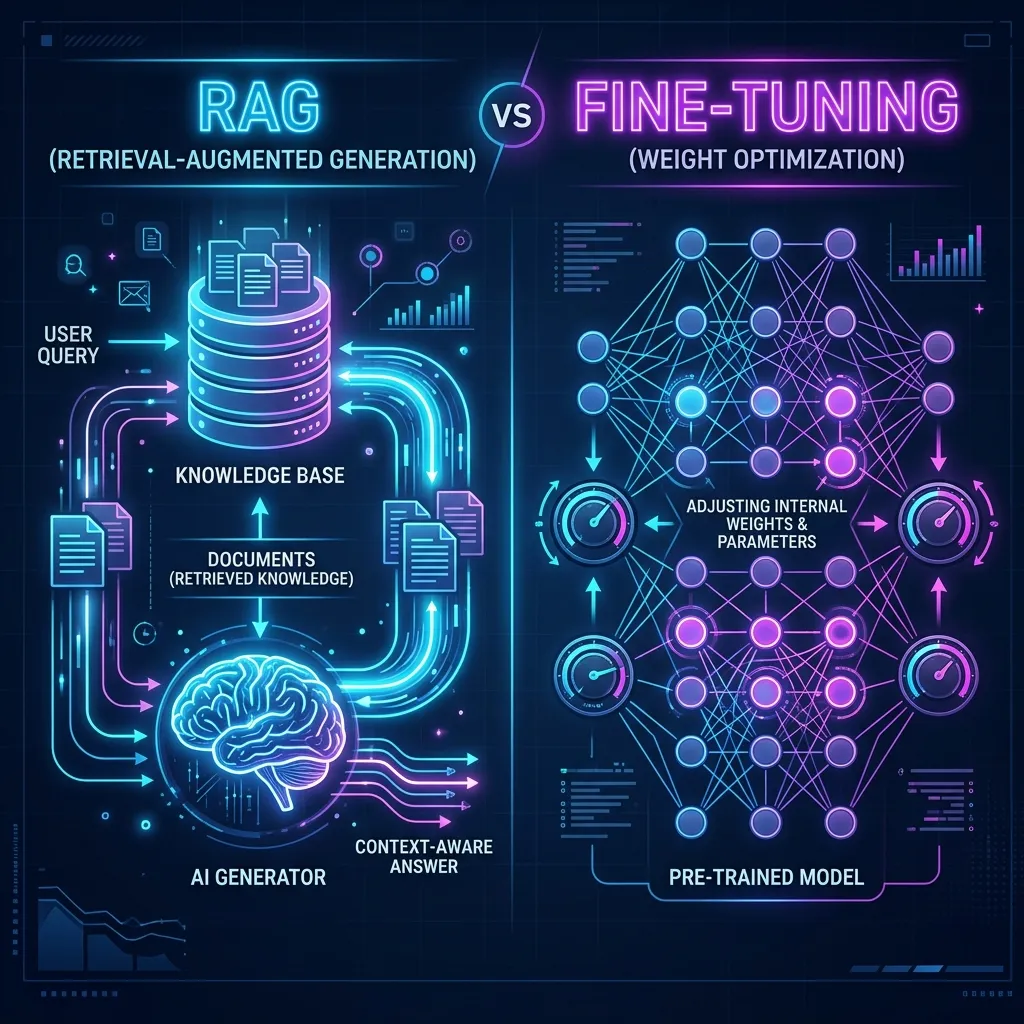
RAG adalah arsitektur dinamis yang mengambil (retrieve) dokumen relevan dari sumber data eksternal dan memasukkannya ke dalam prompt context model secara real-time pada saat query dijalankan.
Alih-alih mencoba memasukkan semua informasi langsung ke dalam weight internal model, RAG memperlakukan LLM sebagai “in-memory processor” dan vector database sebagai “hard drive”.
User Query -> Embedding Model -> Vector DB Retrieval -> Prompt Construction -> LLM -> OutputKelebihan RAG
- Tanpa Training: Tidak perlu menghabiskan waktu komputasi yang lama untuk melatih neural network weights.
- Update Dinamis: Jika dokumen internal Kamu berubah, Kamu hanya perlu memperbarui indeks di vector database. LLM akan segera memiliki akses ke pengetahuan baru tersebut tanpa perlu retraining.
- Kemudahan Audit (Traceability): Karena dokumen sumber dimasukkan ke dalam prompt, model dapat mengutip sumbernya, sehingga memudahkan pengguna untuk memverifikasi jawaban.
- Mengurangi Halusinasi: Dengan membatasi model pada konteks eksplisit yang diberikan, tingkat jawaban halusinasi dapat dikurangi secara signifikan.
Kekurangan RAG
- Batas Context Window: RAG dibatasi oleh batas token maksimum dari context window LLM yang digunakan.
- Kompleksitas Ingestion Pipeline: Kamu harus memelihara pipeline untuk memproses dokumen, strategi pemotongan teks (chunking), model embedding, dan database vektor.
- Tidak Mengubah Perilaku Model: RAG tidak mengajarkan gaya penulisan atau perilaku baru kepada model; pendekatan ini hanya menyediakan informasi tambahan.
Memahami Fine-Tuning
Fine-Tuning adalah proses mengambil base model yang sudah dilatih sebelumnya (pre-trained) dan melatih parameter internalnya lebih lanjut menggunakan dataset khusus yang telah dikurasi.
Melalui proses backpropagation, model menyesuaikan bobot (weights) internalnya untuk lebih memahami nuansa dari data training tersebut.
Pre-trained LLM + Specialized Dataset -> Training Run (Backpropagation) -> Fine-Tuned ModelKelebihan Fine-Tuning
- Adaptasi Domain: Sangat baik untuk mengajarkan model terminologi khusus, sintaksis kode internal, atau format output tertentu (seperti schema JSON).
- Latency & Efisiensi: Karena pengetahuan sudah diinternalisasi ke dalam bobot model, Kamu tidak perlu mengirimkan dokumen konteks yang besar pada setiap panggilan API. Hal ini mengurangi penggunaan token prompt dan latency.
- Konsistensi Gaya & Nada: Memungkinkan Kamu mengarahkan persona, nada bicara, batas keamanan (safety boundaries), dan struktur respons model secara konsisten.
Kekurangan Fine-Tuning
- Pengetahuan Bersifat Statis: Pengetahuan model terkunci pada saat proses training selesai. Untuk memperbaruinya dengan fakta-fakta baru, Kamu harus melakukan training ulang atau incremental fine-tuning.
- Biaya Training Tinggi: Membutuhkan resource compute GPU yang mahal, kurasi dataset yang intensif, serta keahlian machine learning.
- Risiko Halusinasi: Model yang di-fine-tune masih bisa melakukan halusinasi fakta karena tidak memiliki mekanisme kutipan sumber secara langsung.
Dimensi Perbandingan Utama
Untuk memilih antara RAG dan Fine-Tuning, developer perlu mengevaluasi empat dimensi inti berikut:
1. Kesegaran Data dan Dinamika Informasi
Jika data Kamu terus berubah setiap saat (misalnya: harga saham terbaru, inventaris barang per jam, atau tiket support pelanggan), RAG adalah satu-satunya pilihan yang layak. Fine-Tuning bersifat statis; memperbaruinya secara terus-menerus untuk mencerminkan perubahan real-time tidak praktis secara komputasi dan sangat mahal.
2. Perilaku, Struktur, dan Format Output
Jika Kamu membutuhkan model untuk menghasilkan format keluaran yang sangat spesifik (seperti sintaks SDK custom, bahasa pemrograman internal, atau struktur JSON yang ketat), Fine-Tuning adalah solusinya. Meskipun Kamu dapat mengarahkan model RAG menggunakan prompt untuk menghasilkan JSON, model hasil fine-tuning dapat melakukannya jauh lebih andal dan efisien.
3. Risiko Halusinasi dan Audit Fakta
Untuk sistem yang kritis (hukum, medis, keuangan) di mana kesalahan informasi bisa berdampak fatal, RAG jauh lebih unggul karena mendasarkan jawabannya pada dokumen referensi nyata dan mendukung kutipan dokumen. Fine-Tuning mengajarkan model bagaimana cara berbicara, tetapi tidak mencegahnya membuat-buat fakta jika pertanyaan di luar data training.
4. Biaya Setup dan Maintenance
- RAG memiliki kompleksitas operasional yang lebih tinggi di sisi runtime (mengelola search vector dan pipeline chunking) tetapi biaya upfront-nya sangat rendah.
- Fine-Tuning membutuhkan biaya awal yang sangat tinggi (persiapan data, pelabelan, waktu komputasi GPU) tetapi kompleksitas inferensinya lebih rendah karena prompt tetap pendek.
Matriks Perbandingan
| Dimensi | Retrieval-Augmented Generation (RAG) | Fine-Tuning |
|---|---|---|
| Tujuan Utama | Akses informasi & pembuktian fakta | Adaptasi gaya, format, dan perilaku |
| Basis Pengetahuan | Dinamis (diperbarui dengan indeks file) | Statis (terkunci pada waktu training) |
| Risiko Halusinasi | Rendah (dibatasi oleh konteks prompt) | Sedang-Tinggi (bergantung pada bobot model) |
| Kutipan Sumber | Ya (didukung secara bawaan) | Tidak (tidak dapat mengutip bobot internal) |
| Biaya Awal (Upfront) | Rendah (tidak membutuhkan training) | Tinggi (butuh GPU & dataset berlabel) |
| Biaya Inferensi | Tinggi (prompt panjang karena dokumen konteks) | Rendah (prompt ringkas) |
| Keahlian Tim | Software Engineering / Database | Machine Learning / Data Science |
Kerangka Keputusan: Kapan Menggunakan Apa
Untuk membantu menentukan keputusan arsitektur Anda, gunakan alur berikut:
graph TD
A[Identifikasi Kebutuhan Utama] --> B{Butuh Informasi Dinamis/Real-time?}
B -- Ya --> C[Gunakan RAG]
B -- No --> D{Butuh Format Ketat, Persona khusus, atau Performa Tugas Spesifik?}
D -- Ya --> E[Gunakan Fine-Tuning]
D -- No --> F[Gunakan Prompt Engineering / RAG]
Pilih RAG jika:
- Sumber data Kamu berubah secara konstan.
- Respons terhadap query pengguna wajib mencantumkan sumber referensi atau link dokumen asal.
- Kamu perlu mengatur izin akses dokumen secara dinamis (misalnya: user hanya boleh mencari dokumen yang sesuai hak aksesnya).
- Kamu ingin meluncurkan MVP dengan cepat tanpa harus menyusun dataset training yang besar.
Pilih Fine-Tuning jika:
- Kamu ingin model berbicara dengan gaya khusus, menulis kode menggunakan framework internal, atau mengikuti panduan gaya yang ketat.
- Kamu ingin meminimalkan latency dan menghemat biaya token dengan menjaga prompt sistem tetap pendek.
- Kamu ingin mengoptimalkan model yang lebih kecil (misalnya: parameter 8B) agar bekerja sebaik model umum yang lebih besar (misalnya: 70B) untuk satu tugas khusus.
- Kamu sedang membangun aplikasi offline yang tidak dapat melakukan query ke database eksternal.
Pendekatan Hybrid: RAG + Fine-Tuning
Bagi banyak aplikasi enterprise, solusi ideal bukanlah memilih salah satu, melainkan menggabungkan keduanya.
Dalam arsitektur hybrid:
- Kamu melakukan Fine-Tune pada model agar menguasai format output yang ketat (misalnya: penulisan query SQL atau payload API), gaya komunikasi perusahaan, dan batasan keamanan.
- Kamu menggunakan pipeline RAG untuk menyuntikkan schema database terbaru atau dokumentasi terbaru ke dalam prompt model hasil fine-tune tersebut secara real-time.
Dengan cara ini, Kamu mendapatkan hasil terbaik: model yang memahami bagaimana cara menyusun jawaban dengan tepat, menggunakan fakta-fakta yang paling akurat dan up-to-date.
FAQ
Apakah RAG lebih murah dibanding Fine-Tuning?
Ya, dalam hal biaya awal. RAG tidak memerlukan training GPU yang mahal. Namun, karena prompt RAG menyertakan dokumen konteks, biaya penggunaan API per panggilan (token input) jauh lebih mahal dibandingkan model fine-tuned yang menggunakan prompt pendek.
Bisakah Fine-Tuning mengajarkan fakta baru kepada model?
Bisa, tetapi tidak efisien. Model dapat menginternalisasi fakta baru selama training, tetapi ini membutuhkan paparan berulang-ulang di banyak epoch training dan berisiko mengalami overfitting. Jika tujuan utama Kamu adalah memberi tahu model fakta baru, gunakan RAG.
Apakah saya membutuhkan database vektor untuk RAG?
Ya, untuk skala data production. Meskipun Kamu dapat mencari file teks secara manual atau menggunakan pencarian keyword biasa untuk data yang sangat kecil, database vektor memungkinkan pencarian semantik yang cepat di antara jutaan potongan dokumen dengan latency yang sangat rendah.
Referensi
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks - arXiv
- Fine-Tuning Large Language Models: Guide and Best Practices - OpenAI
- Pinecone - RAG vs Fine-Tuning Overview
Artikel Terkait
- Bangun RAG untuk Internal Knowledge Base Tim Engineering
- Machine Learning Model Deployment: Dari Training ke Production
- Observability 101: Logs, Metrics, Traces untuk Tim Modern
Arsitektur RAG ibarat ujian open-book: model dapat mencari dan membaca informasi apa saja yang dibutuhkan. Fine-Tuning ibarat belajar berminggu-minggu untuk menginternalisasi materi: model mengubah cara berpikir dan merespons secara mendasar.
Dalam proyek Kamu saat ini, apakah Kamu lebih mengandalkan RAG, Fine-Tuning, atau mulai merancang pipeline hybrid untuk menggabungkan kelebihan keduanya? Bagikan pendapat Kamu di kolom komentar di bawah!