RAG vs Fine-Tuning: When to Use Each Approach
Table of Contents
- Introduction
- Understanding RAG (Retrieval-Augmented Generation)
- Understanding Fine-Tuning
- Key Comparison Dimensions
- Comparison Matrix
- The Decision Framework: When to Use What
- The Hybrid Approach: RAG + Fine-Tuning
- FAQ
- Conclusion
Introduction
When building enterprise generative AI applications, developers face a critical design question: how do we adapt a Large Language Model (LLM) to work with our proprietary data and perform specific tasks?
Broadly, two primary methodologies dominate the landscape: Retrieval-Augmented Generation (RAG) and Fine-Tuning. While they are often discussed as competing alternatives, they solve fundamentally different problems. RAG is primarily about giving the model access to external, dynamic knowledge, whereas Fine-Tuning is about modifying the model’s behavior, style, or task-specific performance.
Choosing the wrong approach can lead to high compute costs, stale data, and poor user experiences. This article compares RAG and Fine-Tuning across key dimensions to help you choose the best architectural pattern for your application.
Understanding RAG (Retrieval-Augmented Generation)
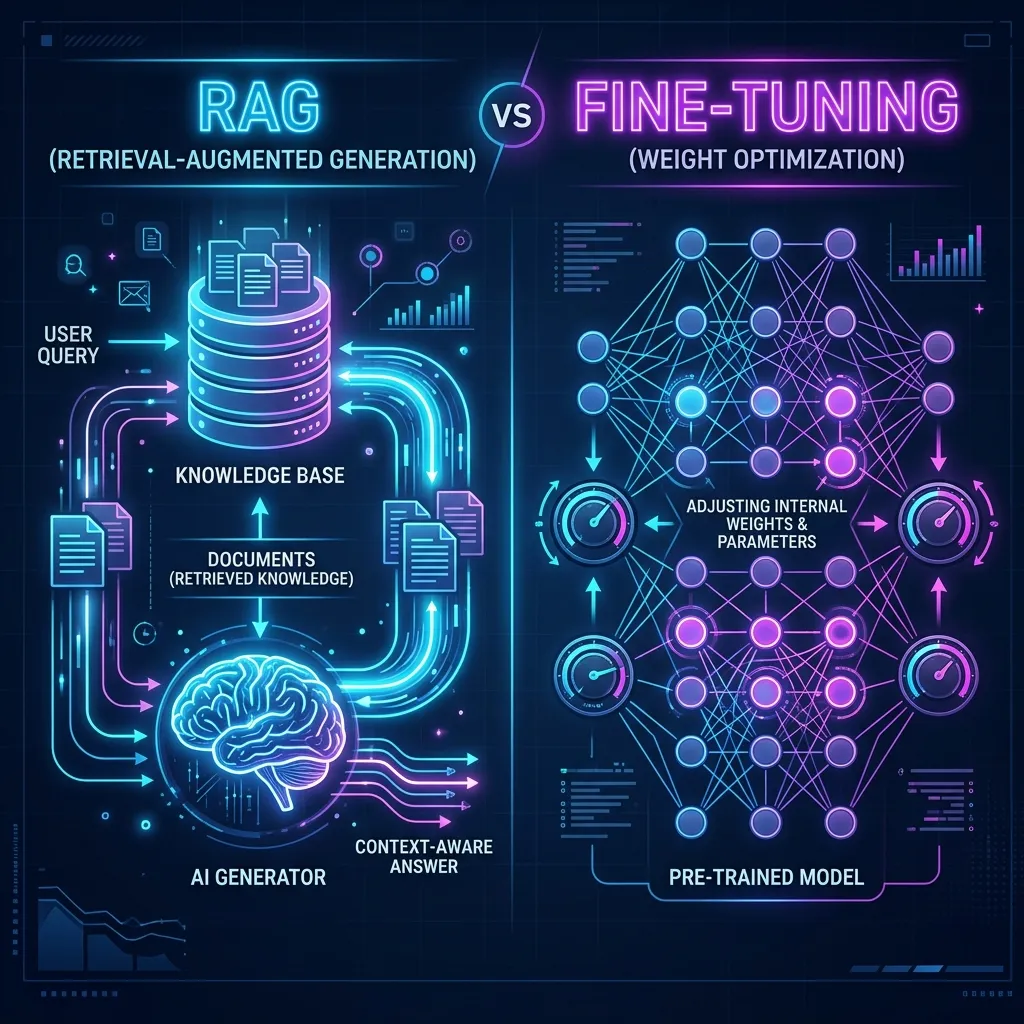
RAG is a dynamic architecture that retrieves relevant documents from an external data source and injects them into the model’s prompt context at runtime.
Instead of trying to bake all information directly into the model’s internal weights, RAG treats the LLM as an “in-memory processor” and the vector database as the “hard drive.”
User Query -> Embedding Model -> Vector DB Retrieval -> Prompt Construction -> LLM -> OutputAdvantages of RAG
- Zero Training Required: No need to spend compute hours training neural network weights.
- Dynamic Updates: If your internal documents change, you only update the index in the vector database. The LLM immediately has access to the fresh knowledge without retraining.
- Traceability: Because source documents are loaded into the prompt, the model can cite its sources, allowing users to audit the answers.
- Hallucination Mitigation: Grounding the model in explicit context significantly reduces the rate of hallucinated facts.
Disadvantages of RAG
- Context Window Limits: RAG is constrained by the maximum token limit of the LLM’s context window.
- Complex Retrieval Pipelines: You must maintain an ingestion pipeline, document chunking strategy, embedding models, and a vector database.
- No Style Modification: RAG does not teach the model new formatting styles or behaviors; it only provides information.
Understanding Fine-Tuning
Fine-Tuning is the process of taking a pre-trained base model and training its weights further on a specific, curated dataset.
Through backpropagation, the model adapts its internal parameters to better understand the nuances of the training data.
Pre-trained LLM + Specialized Dataset -> Training Run (Backpropagation) -> Fine-Tuned ModelAdvantages of Fine-Tuning
- Domain Adaptation: Excellent for teaching the model specialized terminology, syntax, code bases, or output formats (e.g., JSON schemas).
- Latency & Efficiency: Because the knowledge is internalized in the model weights, you do not need to pass large context chunks in every API call, which reduces prompt token usage and latency.
- Consistent Style & Tone: Allows you to steer the model’s persona, tone, safety boundaries, and response structures consistently.
Disadvantages of Fine-Tuning
- Static Knowledge: The model’s knowledge is frozen at the time of the training run. Updating it with new facts requires a new training epoch or incremental fine-tuning.
- High Training Costs: Requires GPU compute resources, dataset curation, and machine learning expertise.
- Hallucination Risk: Fine-tuned models can still confidently hallucinate facts because they lack direct source citation mechanisms.
Key Comparison Dimensions
To choose between RAG and Fine-Tuning, developers must evaluate four core dimensions:
1. Data Freshness and Dynamics
If your dataset changes frequently (e.g., stock prices, hourly inventory, customer support tickets), RAG is the only viable option. Fine-Tuning is static; updating it continuously to reflect real-time changes is computationally impractical and expensive.
2. Behavior, Structure, and Formatting
If you need the model to output specific formats (like custom SDK syntax, domain-specific programming languages, or strict JSON structures), Fine-Tuning excels. While you can prompt a RAG model to output JSON, a fine-tuned model does so far more reliably and with less overhead.
3. Hallucination Risk and Auditing
For critical systems (legal, medical, financial) where errors can be disastrous, RAG is superior because it grounds the output in retrieved reference text and supports document citations. Fine-Tuning teaches the model how to speak, but it does not prevent it from hallucinating facts if the prompt falls outside its training distribution.
4. Setup and Maintenance Cost
- RAG has higher operational complexity at runtime (managing vector search, chunking pipelines) but low upfront cost.
- Fine-Tuning has very high upfront costs (data preparation, labeling, GPU training time) but lower inference complexity because prompts remain short.
Comparison Matrix
| Dimension | Retrieval-Augmented Generation (RAG) | Fine-Tuning |
|---|---|---|
| Primary Goal | Knowledge access & factual grounding | Style, format, and behavior adaptation |
| Knowledge Base | Dynamic (updated by indexing files) | Static (frozen at training time) |
| Hallucination Risk | Low (grounded in context) | Moderate-High (relies on weights) |
| Source Citation | Yes (supported natively) | No (cannot cite weights) |
| Upfront Cost | Low (no training needed) | High (GPU time & labeled dataset) |
| Inference Cost | High (large prompts with context) | Low (short prompts) |
| Implementation Skill | Software Engineering / Databases | Machine Learning / Data Science |
The Decision Framework: When to Use What
To decide, use the following rules of thumb:
graph TD
A[Identify Main Requirement] --> B{Need Dynamic/Real-time Knowledge?}
B -- Yes --> C[Use RAG]
B -- No --> D{Need Strict Formatting, Persona, or Specialized Task Performance?}
D -- Yes --> E[Use Fine-Tuning]
D -- No --> F[Use Prompt Engineering / RAG]
Choose RAG when:
- Your source data changes constantly.
- User query responses must include clickable sources or citations.
- You need to control document access permissions dynamically (e.g., users should only retrieve files they are authorized to see).
- You want to launch an MVP quickly without compiling large training datasets.
Choose Fine-Tuning when:
- You need the model to speak a specialized dialect, write code in an internal language, or follow a strict style guide.
- You want to minimize latency and token costs by keeping the system prompt short.
- You need to optimize a smaller model (e.g., 8B parameters) to perform as well as a larger general model (e.g., 70B) on a narrow, specific task.
- You are building an offline application where remote databases cannot be queried.
The Hybrid Approach: RAG + Fine-Tuning
For many enterprise applications, the ideal solution is not choosing one over the other, but combining both.
In a hybrid architecture:
- You Fine-Tune a model to master the specific formatting (e.g., SQL generation or API payload structure), corporate voice, and safety boundaries.
- You implement a RAG pipeline to inject the latest database schemas or documentation into the prompt of that fine-tuned model at runtime.
This gives you the best of both worlds: a model that understands how to output structured answers precisely, using the most accurate, up-to-date facts available.
FAQ
Is RAG cheaper than Fine-Tuning?
Yes, in terms of upfront costs. RAG requires no expensive GPU training runs. However, because RAG prompts include retrieved documents, your API usage cost per call (input tokens) is significantly higher than a fine-tuned model that uses short prompts.
Can Fine-Tuning teach a model new facts?
Yes, but inefficiently. Models can internalize new facts during fine-tuning, but this requires repeated exposure across many training epochs, risking overfitting. If you just need the model to know new facts, use RAG.
Do I need a vector database for RAG?
Yes, for production-scale data. While you can search text files manually or use basic keyword matching for tiny datasets, a vector database enables fast semantic retrieval over millions of chunks at low latency.
References
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks - arXiv
- Fine-Tuning Large Language Models: Guide and Best Practices - OpenAI
- Pinecone - RAG vs Fine-Tuning Overview
Related Articles
- Build RAG for an Internal Engineering Knowledge Base
- Machine Learning Model Deployment: From Training to Production
- Observability 101: Logs, Metrics, and Traces for Modern Teams
A RAG architecture is like having an open-book exam: the model can look up anything it needs. Fine-Tuning is like studying for weeks to internalize the subject: the model changes how it thinks and responds.
In your current projects, are you relying more on RAG or Fine-Tuning, or have you started designing hybrid pipelines to combine their benefits? Share your thoughts in the comment section below!