Incident Response Buat Tim Kecil: Tetap Tenang Saat Production Error
Daftar Isi
- Kenapa Incident Response Penting untuk Tim Kecil?
- Framework Incident Response untuk Tim Kecil
- Fase 1: Deteksi & Acknowledgment (0-5 menit)
- Fase 2: Investigasi & Triage (5-30 menit)
- Fase 3: Resolution & Recovery (30+ menit)
- Fase 4: Post-Mortem & Learning
- Communication Templates
- Tooling untuk Tim Kecil
- Common Pitfalls & Solutions
- Checklist Incident Response
Kenapa Incident Response Penting untuk Tim Kecil?
Tim kecil sering menghadapi tantangan unik saat production error terjadi:
- Sumber daya terbatas - hanya beberapa orang yang tersedia
- Tekanan tinggi - setiap orang memegang banyak peran
- Dampak pelanggan - error langsung terasa oleh pengguna
- Kesempatan belajar - setiap incident adalah kesempatan untuk perbaikan
Incident response yang baik bukan tentang mencegah error - ini tentang meminimalkan kerusakan dan belajar dari pengalaman.
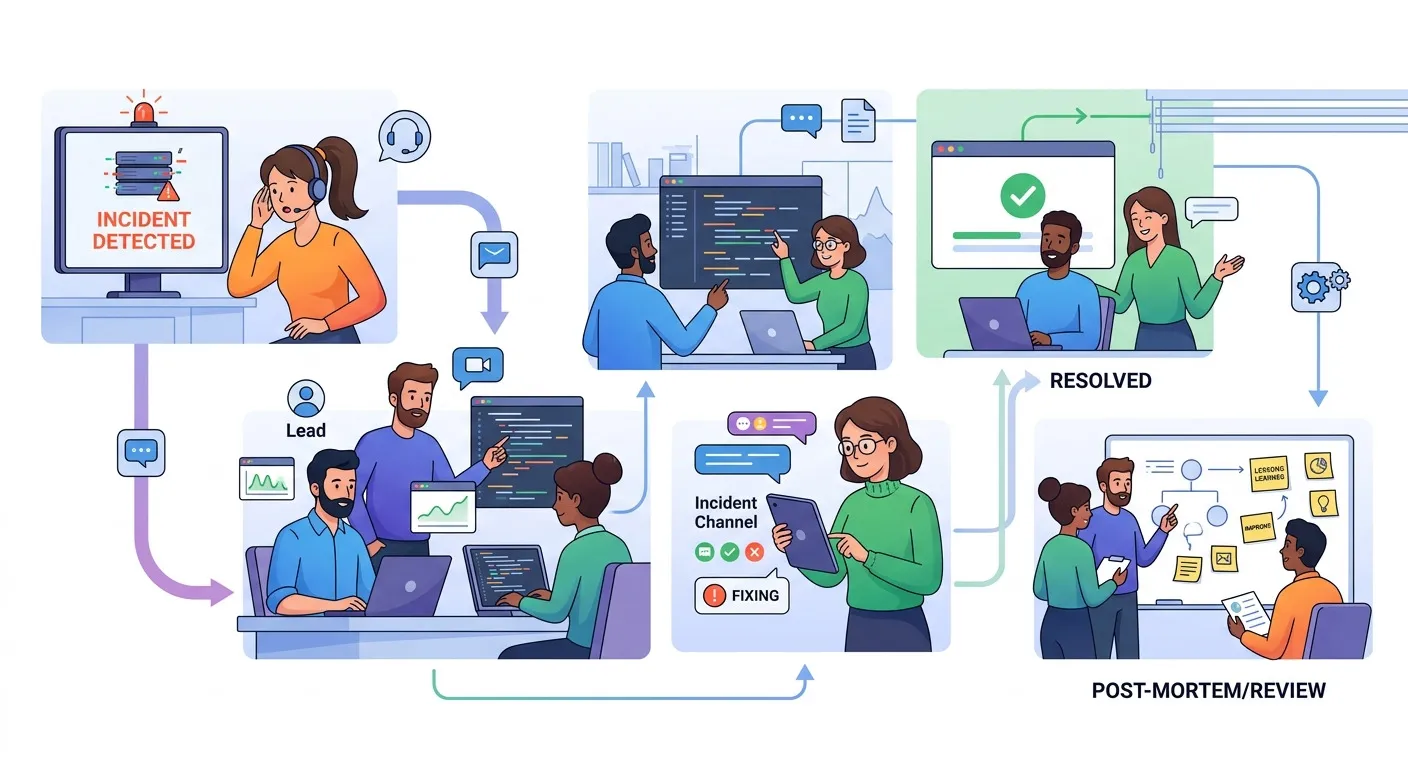
Framework Incident Response untuk Tim Kecil
Framework ini disesuaikan untuk tim 2-5 orang dengan fokus pada kecepatan dan kejelasan:
Timeline Incident Response:
├── 0-5 menit: Deteksi & Acknowledgment
│ ├── Monitor alert terpicu
│ ├── Penilaian dampak awal
│ ├── Deklarasi incident & buat channel
│ └── Komunikasikan status
├── 5-30 menit: Investigasi & Triage
│ ├── Kumpulkan konteks & log
│ ├── Identifikasi area root cause
│ ├── Tentukan tingkat severity
│ └── Tunjuk incident commander
├── 30+ menit: Resolution & Recovery
│ ├── Implementasi perbaikan (sementara/permanen)
│ ├── Monitor pemulihan
│ ├── Verifikasi pemulihan layanan
│ └── Update stakeholder
└── Post-Incident: Pembelajaran
├── Tulis post-mortem
├── Identifikasi action items
├── Update proses
└── Bagikan pembelajaranFase 1: Deteksi & Acknowledgment (0-5 menit)
Alert Detection
Setup monitoring yang komprehensif tapi tidak overwhelming:
# Contoh alert configuration
alerts:
critical:
- service_down_5min
- error_rate_50percent
- response_time_5x_baseline
warning:
- error_rate_increase_20percent
- memory_usage_80percent
- queue_depth_1000Initial Response Script
Orang yang pertama mendeteksi incident harus:
-
Acknowledge segera di monitoring system
-
Buat incident channel di Slack/Teams
-
Post update awal dengan template:
🚨 INCIDENT DECLARED 🚨 Service: [Nama Service] Time: [Timestamp] Impact: [Initial assessment] Severity: [Critical/High/Medium/Low] Next update in 15 minutes or when new info available. -
Tag orang yang relevan berdasarkan rotasi on-call
Severity Assessment
Gunakan framework ini untuk menentukan severity:
| Severity | Impact | Response Time | Example |
|---|---|---|---|
| Critical | Layanan mati total | < 5 menit | Login tidak berfungsi |
| High | Fitur utama rusak | < 15 menit | Payment processing gagal |
| Medium | Degrade parsial | < 1 jam | Reports lambat |
| Low | Issue minor | < 4 jam | UI glitch |
Fase 2: Investigasi & Triage (5-30 menit)
Role Assignment
Untuk tim kecil, assign roles yang fleksibel:
incident_roles:
incident_commander:
responsibilities:
- Koordinasi response
- Kelola komunikasi
- Buat keputusan final
backup: "Senior engineer on-call"
technical_lead:
responsibilities:
- Pimpin investigasi
- Koordinasi perbaikan teknis
- Verifikasi resolusi
backup: "Any available engineer"
communications_lead:
responsibilities:
- Update stakeholder
- Kelola komunikasi pelanggan
- Dokumentasi timeline
backup: "Product manager or support lead"Investigation Process
Langkah 1: Kumpulkan Konteks (5-10 menit)
- Cek deployment terbaru
- Review error log dan metrik
- Identifikasi komponen yang terpengaruh
- Cek dependensi eksternal
Langkah 2: Isolasi Masalah (10-20 menit)
- Reproduksi issue di staging
- Test hipotesis
- Perkecil area root cause
- Dokumentasi temuan di incident channel
Langkah 3: Tentukan Strategi Perbaikan (20-30 menit)
fix_strategy:
immediate_actions:
- Rollback deployment?
- Restart services?
- Scale resources?
- Fallback ke cached data?
permanent_solution:
- Code fix needed?
- Configuration change?
- Infrastructure update?
- Process improvement?Fase 3: Resolution & Recovery (30+ menit)
Implementation Guidelines
Untuk perbaikan sementara:
- Prioritaskan kecepatan daripada kesempurnaan
- Dokumentasi apa yang diubah
- Set reminder untuk perbaikan permanen
- Monitor efek samping
Untuk perbaikan permanen:
- Test di staging terlebih dahulu
- Rencanakan strategi rollback
- Komunikasikan maintenance window
- Monitor post-deployment
Recovery Verification
Checklist untuk verifikasi:
- Service health checks berhasil
- Key user journeys berfungsi
- Metrik kembali ke baseline
- Tidak ada error baru di log
- Laporan pelanggan terselesaikan
Communication Updates
Update setiap 15-30 menit atau saat ada perubahan signifikan:
📊 INCIDENT UPDATE 📊
Status: [Investigating/Mitigated/Resolved]
Time: [Timestamp]
Impact: [Current state]
Actions: [What we've done]
ETA: [If available]
Next update: [Time or "when new info"]Fase 4: Post-Mortem & Learning
Blameless Post-Mortem Template
# Incident Post-Mortem: [Incident Title]
## Summary
[Brief description of what happened and impact]
## Timeline
- **HH:MM**: Alert triggered
- **HH:MM**: Incident declared
- **HH:MM**: Root cause identified
- **HH:MM**: Fix implemented
- **HH:MM**: Service restored
## Root Cause
[What actually caused the incident]
## Impact
- Users affected: [Number/Percentage]
- Duration: [Time]
- Business impact: [Description]
## What Went Well
- [Positive aspects of response]
## What Could Be Improved
- [Areas for improvement]
## Action Items
- [ ] [Specific action] - [Owner] - [Due date]
- [ ] [Specific action] - [Owner] - [Due date]Learning Loop
- Review action items dalam 1 minggu
- Update monitoring berdasarkan pembelajaran
- Perbaiki proses dan dokumentasi
- Bagikan pembelajaran dengan seluruh tim
- Update on-call training jika diperlukan
Communication Templates
Customer Communication
Notifikasi Awal:
Subject: Service Issue - [Service Name]
Hi [Customer Name],
We're currently experiencing issues with [service description].
Our team is actively investigating and working to resolve this.
We'll provide updates every [X] minutes until this is resolved.
Thank you for your patience.
Team [Company Name]Notifikasi Resolusi:
Subject: Resolved - Service Issue - [Service Name]
Hi [Customer Name],
The issue with [service description] has been resolved.
Service is now operating normally.
We're conducting a full review to prevent this from happening again.
If you continue to experience issues, please contact support.
Thank you for your patience.
Team [Company Name]Internal Stakeholder Updates
Ringkasan Eksekutif:
🚨 PRODUCTION INCIDENT 🚨
Service: [Layanan]
Severity: [Level]
Impact: [Dampak bisnis]
Timeline: [Start - Resolution]
Root Cause: [Deskripsi singkat]
Customer Impact: [Number/Type]
Next Steps: [Post-mortem dijadwalkan]Tooling untuk Tim Kecil
Essential Tools
monitoring:
- Application performance monitoring (APM)
- Infrastructure monitoring
- Log aggregation
- Alert management
communication:
- Incident response platform (Slack/Teams)
- Status page
- Email notification system
- Video conferencing
documentation:
- Runbook repository
- Post-mortem template
- Contact information
- Service topologyTools yang Direkomendasikan untuk Tim Kecil
Monitoring:
- Uptime monitoring: UptimeRobot, Pingdom
- APM: Sentry, New Relic (free tier)
- Logs: Papertrail, Logtail
- Metrics: Prometheus + Grafana (self-hosted)
Communication:
- Incident channel: Slack #incidents
- Status page: Statuspage.io, Cachet
- Documentation: Notion, Confluence
Automation:
- Alert routing: PagerDuty (free tier)
- Runbook execution: GitHub Actions
- Post-mortem: Template + automation
Common Pitfalls & Solutions
Pitfall 1: Tidak Ada Incident Commander yang Jelas
Masalah: Semua orang mencoba memimpin, tidak ada yang bertanggung jawab.
Solusi:
- Tentukan rotasi on-call sebelumnya
- Gunakan matriks eskalasi
- Latih simulasi incident
Pitfall 2: Komunikasi Buruk
Masalah: Stakeholder dibiarkan dalam kegelapan, rumor menyebar.
Solusi:
- Gunakan template komunikasi
- Set interval update rutin
- Over-communicate daripada under-communicate
Pitfall 3: Terburu-buru Memperbaiki Tanpa Pemahaman
Masalah: Membuat situasi lebih buruk saat mencoba membantu.
Solusi:
- Ambil 5 menit untuk menilai sebelum bertindak
- Dokumentasi perubahan sebelum implementasi
- Siapkan rencana rollback
Pitfall 4: Tidak Ada Proses Post-Mortem
Masalah: Incident yang sama terjadi berulang kali.
Solusi:
- Jadwalkan post-mortem dalam 48 jam
- Buat action items spesifik dan dapat ditugaskan
- Track completion action items
Pitfall 5: Alert Fatigue
Masalah: Terlalu banyak alert, peringatan diabaikan.
Solusi:
- Review alert threshold secara rutin
- Implementasi alert grouping
- Gunakan severity levels secara tepat
Checklist Incident Response
Persiapan Pre-Incident
- Jadwal on-call ditentukan dan dikomunikasikan
- Informasi kontak up to date
- Alert monitoring dikonfigurasi dan diuji
- Runbooks dibuat untuk skenario umum
- Template komunikasi disiapkan
- Status page setup dan dikonfigurasi
- Training incident response selesai
Selama Incident (0-5 menit)
- Acknowledge alert di monitoring system
- Buat incident channel
- Post update status awal
- Tag anggota tim yang relevan
- Nilai dampak awal
- Tentukan tingkat severity
Selama Incident (5-30 menit)
- Assign role incident commander
- Kumpulkan log dan metrik
- Identifikasi komponen yang terpengaruh
- Bentuk hipotesis tentang root cause
- Dokumentasi temuan investigasi
- Rencanakan strategi perbaikan
Selama Incident (30+ menit)
- Implementasi perbaikan (sementara atau permanen)
- Monitor pemulihan layanan
- Verifikasi fungsionalitas kunci
- Update stakeholder tentang resolusi
- Tutup incident di monitoring system
Post-Incident (Dalam 48 jam)
- Jadwalkan meeting post-mortem
- Lengkapi timeline incident
- Identifikasi root cause
- Buat action items dengan owner
- Bagikan pembelajaran dengan tim
- Update dokumentasi dan runbooks
Peningkatan Berkelanjutan
- Review action items mingguan
- Update monitoring berdasarkan incident
- Lakukan drill incident triwulanan
- Ukur MTTR (Mean Time to Resolution)
- Rayakan peningkatan dan pembelajaran
Kesimpulan
Incident response yang efektif untuk tim kecil bukan tentang memiliki proses yang sempurna - ini tentang memiliki respons yang konsisten dan terlatih yang dapat diskalakan dengan ukuran tim dan sumber daya.
Prinsip kunci untuk tim kecil:
- Kesederhanaan daripada kompleksitas - proses yang mudah diikuti
- Komunikasi adalah kritis - over-communicate selama incident
- Belajar daripada menyalahkan - fokus pada perbaikan bukan hukuman
- Latihan membuat sempurna - drill dan simulasi rutin
- Tools memungkinkan, orang menyelesaikan - teknologi mendukung, bukan menggantikan
Framework ini memberikan struktur yang cukup untuk konsistensi tapi cukup fleksibel untuk realitas tim kecil. Adapt sesuai kebutuhan tim spesifik kamu, tapi pertahankan prinsip inti: komunikasi yang jelas, role yang terdefinisi, dan komitmen untuk belajar.
Ingat: Incident response yang baik adalah skill yang meningkat dengan latihan. Mulai dari yang kecil, konsisten, dan terus tingkatkan berdasarkan incident nyata.
Artikel Terkait
Pengalaman incident apa yang paling berkesan bagi tim kamu? Bagikan cerita dan pembelajaran di komentar - kita bisa belajar bersama!